Adopting microservices often means more dependencies, and more services you might not control. It also means more requests on the network, increasing the possibility for errors. For these reasons, it’s important to test your services’ behavior when upstream dependencies fail.
Chaos testing is the process of deliberately breaking your services in order to expose weaknesses and improve fault tolerance. Chaos testing can reveal client-side bugs, or identify user-facing failure situations where you might want to display a cached result, instead of returning an error.
In a Kubernetes environment, you can approach chaos testing at different layers - for instance, by deleting pods at random, or shutting off entire nodes.
But failures also happen at the application layer. Infinite loops, broken client libraries - application code can fail in an infinite number of ways! This is where Istio fault injection comes in. You can use Istio VirtualServices to do chaos testing at the application layer, by injecting timeouts or HTTP errors into your services, without actually updating your app code. Let’s see how.
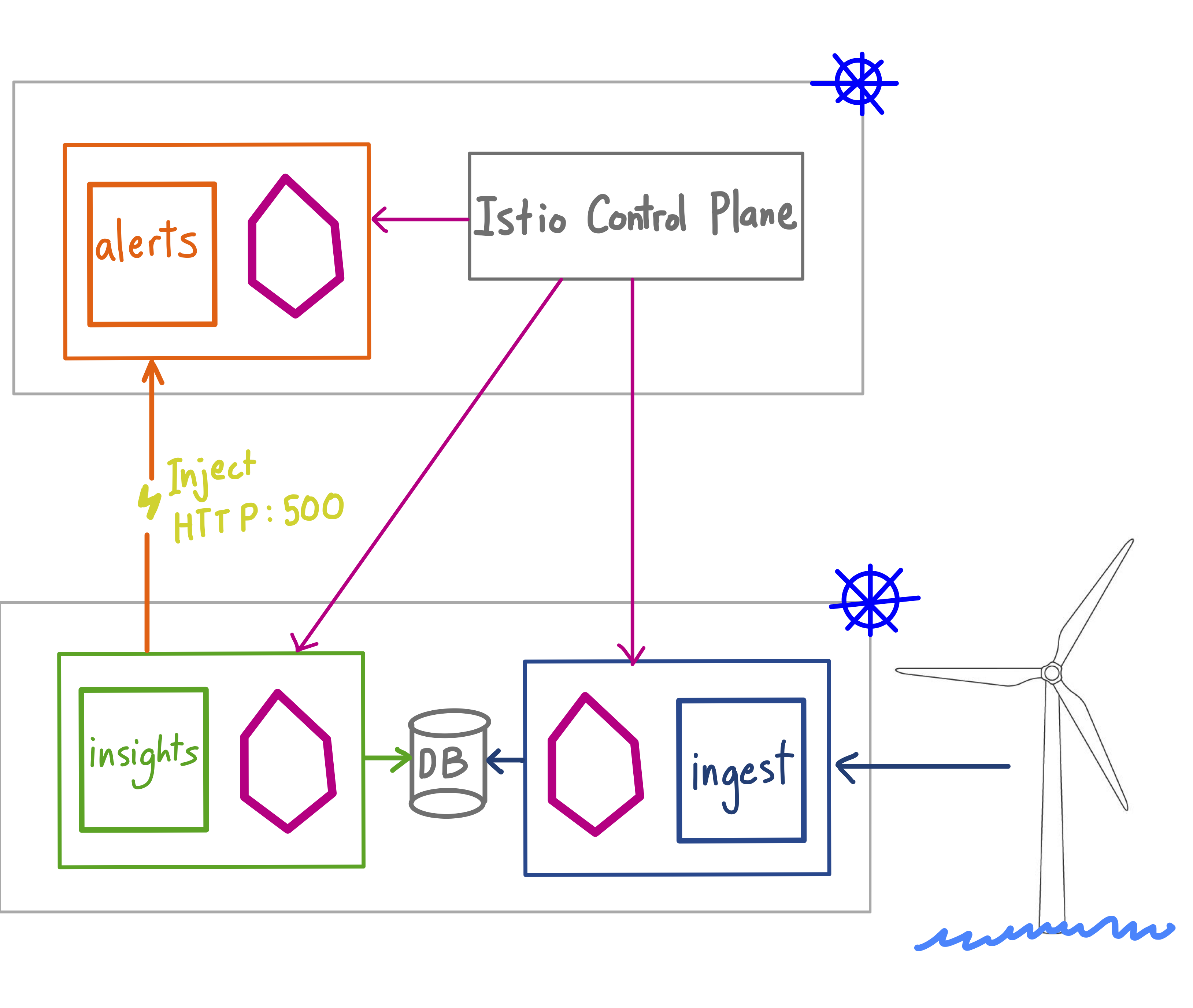
In this example, a wind energy company runs two Kubernetes clusters: one in the cloud, and one in an offshore wind farm. These two clusters are connected together using multicluster Istio, with a single control plane running in the cloud cluster (note - this example would also work in a single-cluster setup). There are three services: ingest processes sensor data from the turbines, and writes to an on-prem timeseries database. insights polls the database to detect anomalies in the power supply, sending a message to alerts, running in the cloud, when there is a potential threat to the power grid.
When the insights service is unable to call home to alerts, we want to ensure that the anomaly does not get lost - ideally, insights will cache the alert, or we use Istio retry logic to send the request again. To test what happens in this failure scenario, we will use Istio to inject a fault into the alerts service: first, we’ll add a 5-second delay, followed by a 500 - Internal Server Error:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: alerts-fault
spec:
hosts:
- alerts
http:
- fault:
abort:
httpStatus: 500
percentage:
value: 100
delay:
percentage:
value: 100
fixedDelay: 5s
route:
- destination:
host: alerts
When we apply this VirtualService, we can curl alerts from the insights application container, and see the configured timeout, followed by a 500 error:
$ curl -v alerts.default.svc.cluster.local:80/
...
* Connected to alerts.default.svc.cluster.local (10.12.10.16) port 80 (#0)
< HTTP/1.1 500 Internal Server Error
...
fault filter abort
And we can examine the insights logs to see how the client side handled that failure.
Note that you can customize these fault injection rules - for instance, fail multiple services at once (by adding more VirtualServices), fail only a percentage of requests, or fail only on certain HTTP request headers (like user-agent, to test the behavior on certain web browsers).
You might also want to create your own chaos testing wrapper around Istio, in order to automate the end-to-end chaos testing process (add fault injection rule, inspect client behavior / state). To do this, you could use the Istio Golang client library to programmatically lifecycle VirtualServices on a cluster.
Sources: